

As global military agencies review their exposure to fitness data published by the Strava social exercise app, Australia’s peak marketing organisation is leveraging its new code of conduct to remind businesses of the potential, unintentional consequences of the open-data economy.
That economy has developed quickly with the publication of large, anonymised data sets by government bodies in Australia, the United States, the UK, and elsewhere. Such data sets – for example, the range of Census DataPacks published by the Australian Bureau of Statistics – offer invaluable insight to marketers, businesses, government agencies and others planning business expansion or service delivery.
Last September, ACS launched its Data Sharing Frameworks technical white paper addressing the challenges for data sharing, including data security, privacy and legal obligations.
Large data sets have also emerged in data-analytics competitions like those hosted at Kaggle. Yet those same data sets often provide more insight than their creators intended, particularly when presented in ways to make it more accessible and informative.
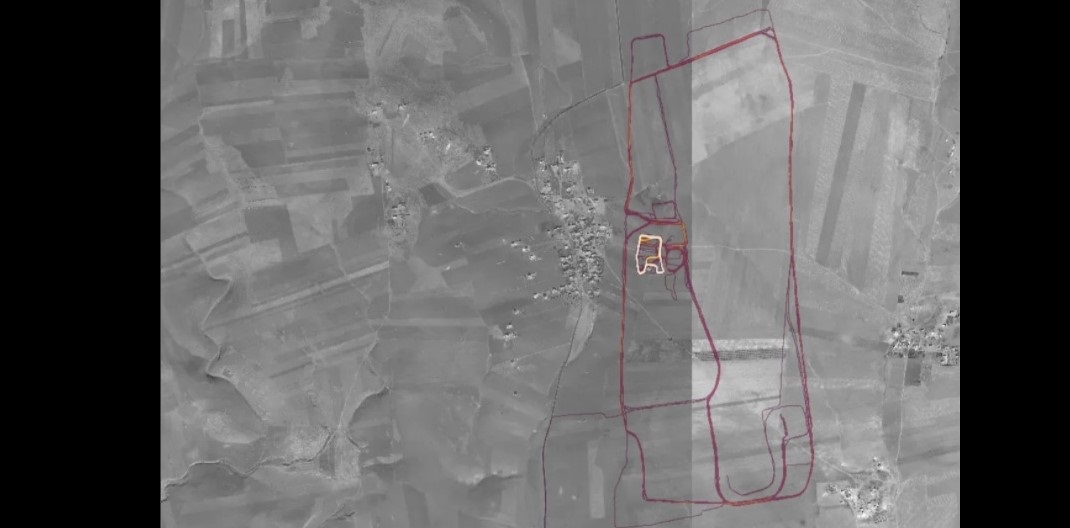
Visualisation is what landed Strava – whose app unites fitness enthusiasts by encouraging them to share their running, cycling, and other activities – in the global spotlight after its new ‘Global Heatmap’ of fitness-tracker activity inadvertently exposed routes used by military personnel while exercising.
Recognising that regular routes around isolated parts of the Middle East could be overlaid onto known military bases, 20-year-old ANU student Nathan Ruser realised that the traces could also identify secret locations – and others, following his lead, found a way to identify individuals at those locations.
Activity tracking and mapping are all within Strava’s terms of service, so the problem was not a conventional privacy breach. Rather, it was that personnel in sensitive areas were conducting a normal civilian activity without considering its potential consequences.
The downside of data
Last month, the International Consortium of Investigative Journalists (ICIJ) leveraged Talend software to build a massive database for cross-matching and analysis of more than 1.4 terabytes of data from the recent Paradise Papers financial documents leak.
Such targeted use of analytics tools has become increasingly frequent as today’s data-driven economies lean on ubiquitous smartphones and data analytics to collect and analyse more and more data about people and their activities.
Businesses are hungry for this data, which can be invaluable in improving customer relationships and profitability, but the potential for abuse has driven an effort by the Association for Data-driven Marketing and Advertising (ADMA) to temper marketers’ use of data collection and exploitation.
“Something done with the best intentions, and that is quite a clever use of data, will have unintended consequences,” ADMA CEO Jodie Sangster said. “As much as we think through how data is going to be used, I am not sure we can foresee every use that’s going to come out of it.”
Most Australian companies only evaluate their data collection processes against existing Privacy Act requirements, Sangster said, noting that this is why Data Governance Australia (DGA) has incorporated provisions around transparency and ethical use of data into its newly released Code of Practice.
Such controls are intended to get organisations thinking about the consequences of their data collection and publication – particularly given that analytics experts have repeatedly demonstrated that cross-correlation can be ‘re-identified’ – used to reconstruct the original information and link it to individuals.
Cracking the code
In 2016, for example, University of Melbourne data scientists demonstrated that they could re-identify individuals whose identities had been stripped from a Department of Health data dump of one billion historical healthcare records.
And in October, Internet registry APNIC was forced to reset all of its customers’ Whois passwords on concerns that an accidentally-published list of hashed passwords – scrambled using known algorithms and stored to validate users’ identities – could be reverse-engineered to determine the original passwords.
Techniques for reverse-engineering hashes and de-anonymisation of Strava exercise records and other data are widely discussed online, and the practice has burgeoned with the volume of data being collected and analysed.
“Companies have measures in place to protect the data they have,” Sangster said, “but as we collect more data sets, and as data practices are becoming more and more advanced, it’s becoming harder and harder to guarantee that data can’t be de-identified. Businesses are just going to have to constantly be keeping ahead of these practices to ensure the protection of their data.”




