


OPINION
I can’t even browse LinkedIn without seeing some product manager hype about agents coming “just around the corner”.
And before you jump into the comments section, I am not biased.
I’ve worked with large language models since before ChatGPT, when it was GPT-3 in the OpenAI website and it only predicted the next words in the sentence (as opposed to the now-familiar chat interface).
I’ve built AI applications from scratch and trained all types of AI models.
I’ve taken Deep Learning courses at the best AI and Computer Science school in the world, Carnegie Mellon, and obtained my master’s degree there.
And yet, when I see yet another video on my TikTok feed, I can’t help but cringe and think about how “Web 3 was going to transform the internet”.
I swear, this must be bot farms, ignorant non-technical people, and manufactured hype from OpenAI so that they can receive more funding.
I mean, how many software engineers do you know that released production-ready agents?
That’s right. None.
Here’s why all of this manufactured hype is nonsense.
What is an AI agent?
Agents actually have a long history within artificial intelligence.
In recent times, since the invention of ChatGPT, it has come to mean a large language model structured to perform reasoning and complete tasks autonomously.
This model might be fine-tuned with reinforcement learning, but in practice people tend to just use OpenAI’s GPT, Google Gemini, or Anthropic’s Claude.
The difference between an agent and a language model is that agents complete task autonomously.
Here’s an example.
I have an algorithmic trading and financial research platform, NexusTrade.
Let’s say I wanted to stop paying an external data provider to get fundamental data for US companies.
With traditional language models, I would have to write code that interacts with them.
This would look like the following:
- Build a script that scrapes the SEC website or use a GitHub repo to fetch company information (conforming to the 10 requests per second guideline in their terms of service)
- Use a Python library like pypdf to transform the PDFs to text
- Send it to a large language model to format the data
- Validate the response
- Save it in the database
- Repeat for all companies
With an AI agent, you should theoretically just be able to say: ‘Scrape the past and future historical data for all US companies and save it to a MongoDB database.’
Maybe it’ll ask you some clarifying questions.
It might ask if you have an idea for what the schema should look like, or which information is most important.
But the idea is you give it a goal and it will complete the task fully autonomously.
Sounds too good to be true, right?
That’s because it is.
The problem with AI agents in practice
Now if the cheapest, small language model was free, as strong as Claude 3.5, and could run locally on any AWS T2 instance, then this article would be in a completely different tone.
It wouldn’t be a critique. It’d be a warning.
However, as it stands, AI agents do not work in the real world and here’s why.
1. Smaller models are not nearly strong enough
The core problem of agents is that they rely on large language models.
More specifically, they rely on a good model.
GPT-4o mini, the cheapest, large language model, other than Flash, is amazing for the price.
But it is quite simply not strong enough to complete real world agentic tasks.
It will steer off, forget its goals, or just make simple mistakes, no matter how well you prompt it.
And if deployed live, your business will pay the price.
When the large language model makes a mistake, it’s not super easy to detect unless you also build (likely an LLM-based) validation framework.
One small error made at the beginning, and everything downstream from that is cooked.
In practice, here’s how this works.
2. Compounding of errors
Let’s say you’re using GPT-4o-mini for agentic work.
Your agent breaks the task of extracting financial information for a company into smaller subtasks.
Let’s say the probability it does each subtask correctly is 90%.
With this, the errors compound.
If a task is even moderately difficult with four subtasks, the probability of the final output being good is extremely low.
For example, if we break this down:
- The probability of completing one subtask is 90 per cent
- The probability of completing two subtasks is 0.9*0.9 = 81 per cent
- The probability of completing four subtasks is 66 per cent
See where I’m headed?
To mitigate this, you will want to use a better language model.
The stronger model might increase the accuracy of each subtask to 99%.
After four subtasks, the final accuracy is 96%.
A whole lot better (but still not perfect).
Most importantly, changing to these stronger models comes with an explosion in costs.
3. Explosion in costs
Once you switch to the stronger OpenAI models, you will see how your costs explode.
The pink and orange line are the costs of OpenAI’s o1.
I maybe use it 4–5 times per day for extremely intense tasks like generating syntactically valid queries for stock analysis.
The lime green and dark blue line are GPT-4o-mini.
That model sees hundreds of requests every day, and the final costs are a small fraction of what O1 costs.
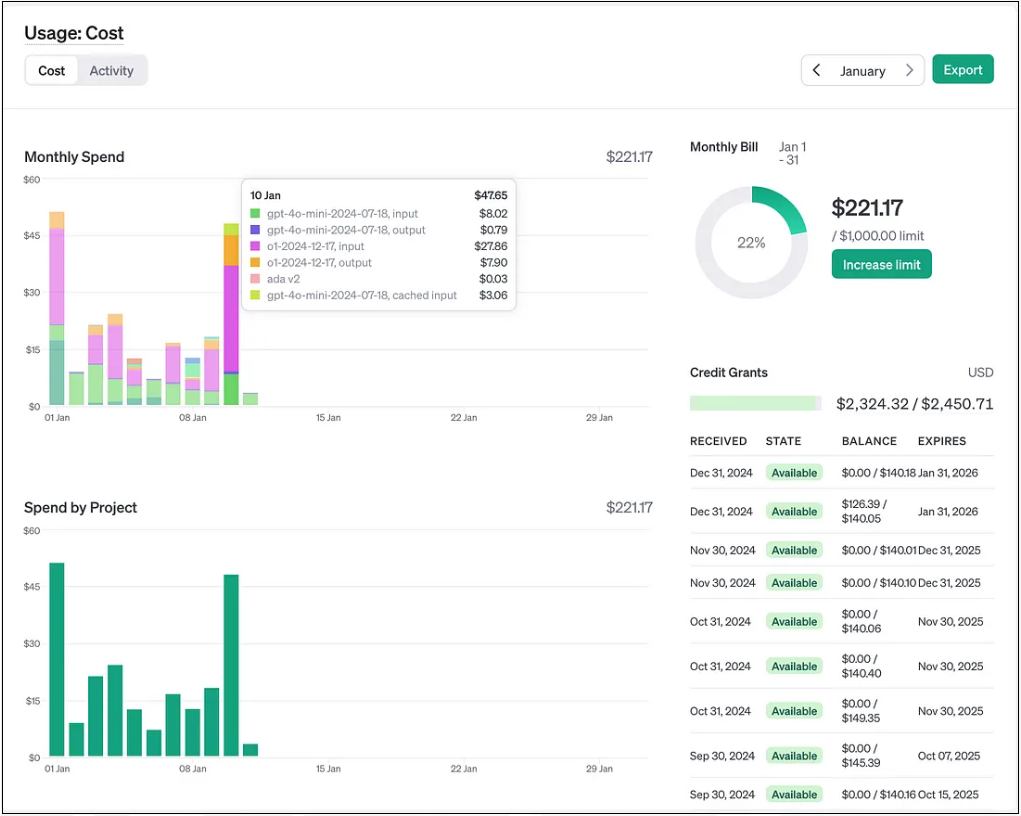
The cost difference between OpenAI’s model of GPT-4o-mini. Graph: Supplied / Austin Starks
Moreover, even after all of this, you still need to validate the final output.
You’re going to be using the stronger models for validation for the same reasons.
So, you use large models for the agent, and you use larger models for validation.
See why I think this is an OpenAI conspiracy?
Finally, changing the world from working with code to working with models has massive side effects.
4. You’re creating work with non-deterministic outcomes
Using LLM agents, the whole paradigm of your work shifts into a data science-esque approach.
Instead of writing deterministic code that is cheap to run everywhere and can run on an arduino (or in practice, a T2 micro-instance from AWS), you are writing non-deterministic prompts for a model running on a cluster of GPUs.
If you’re “lucky”, you are running your own GPUs with fine-tuned models, but it’s still going to cost you an arm and a leg just to maintain agents to do simple tasks.
And if you’re unlucky, you’re completely locked into OpenAI; your prompts outright won’t work if you try to move, and they can slowly increase the price as you’re running critical business processes using their APIs.
And before you say, “you can use OpenRouter to switch models easily”, think again.
The output of Anthropic’s model is different to the output of OpenAI’s.
So, you’ll have to re-prompt engineer your entire stack, costing a fortune, just to get a marginal improvement in final performance for another LLM provider.
Do you see the problem?
Concluding thoughts
It seems almost a certainty that when I see a post about agents, it is from someone that has not used language models in practice.
As you can imagine, this is absolutely infuriating.
I am not saying AI doesn’t have its use-cases.
Even agents can have value a few years from now to assist engineers in writing simple code.
But no reasonable company is going to replace their operations team with a suite of extremely expensive, error-prone agents in order to run critical processes for their business.
And if they try, we will all see with our own eyes how they go bankrupt in two years.
They’ll be a lesson in the business textbooks, and OpenAI will make an additional $1 billion in revenue.
Mark my words.
This article was originally published on Medium and is reproduced with permission. It has been edited for clarity and length. You can read the original article here.




