LinkedIn, Zoom and some of the world's most used websites were taken down Friday evening after web infrastructure provider Cloudflare suffered its second major outage in less than a month.
What initially appeared to users as isolated website crashes quickly revealed itself to be a widescale outage impacting the likes of ecommerce platform Shopify, digital currency exchange Coinbase, self-publishing platform Substack, social network LinkedIn, meetings platform Zoom, and ironically, outage detection service Downdetector.
As swathes of the internet were made inaccessible, Cloudflare chief technology officer Dane Knecht announced on social media platform X the company was “aware of [an] issue impacting the availability of Cloudflare’s network”.
“Sites should be back online now,” Knecht said at 8.20pm AEDT Friday, after sites had been unavailable for 25 minutes.
The company later explained the outage impacted approximately 28 per cent of all traffic served by Cloudflare – which is estimated to service one in five of the world’s websites.
“Any outage of our systems is unacceptable, and we know we have let the internet down again,” Knecht wrote.
Cloudflare did not announce precisely which of its customers were affected, though Downdetector logged over 4,500 reports related to issues at Cloudflare in the moments following the outage.
Cloudflare has promised to publish more information this week about what steps it is taking to prevent “these types of incidents” from occurring.
Two blackouts in less than a month
Friday’s web blackout came after another remarkably large outage in mid-November, when an internal configuration file at Cloudflare grew beyond its expected size and crashed one of the company’s traffic-routing systems.
The outage lasted nearly three hours and impacted such big-name clients as X, ChatGPT, YouTube, design platform Canva, dating app Grindr and many others.
This was not a good look for Cloudflare. Photo: Supplied
While Cloudflare’s November error was triggered after the company adjusted one of its database systems’ permissions, the company explained its Friday outage began following some changes to the internal logic it uses to parse HTTP requests.
After staff disabled one of Cloudflare’s firewall testing tools to enact these changes, a specific subset of clients that had their web assets served by an older proxy server while also using the company’s ‘Cloudflare Managed Ruleset’ feature were impacted.
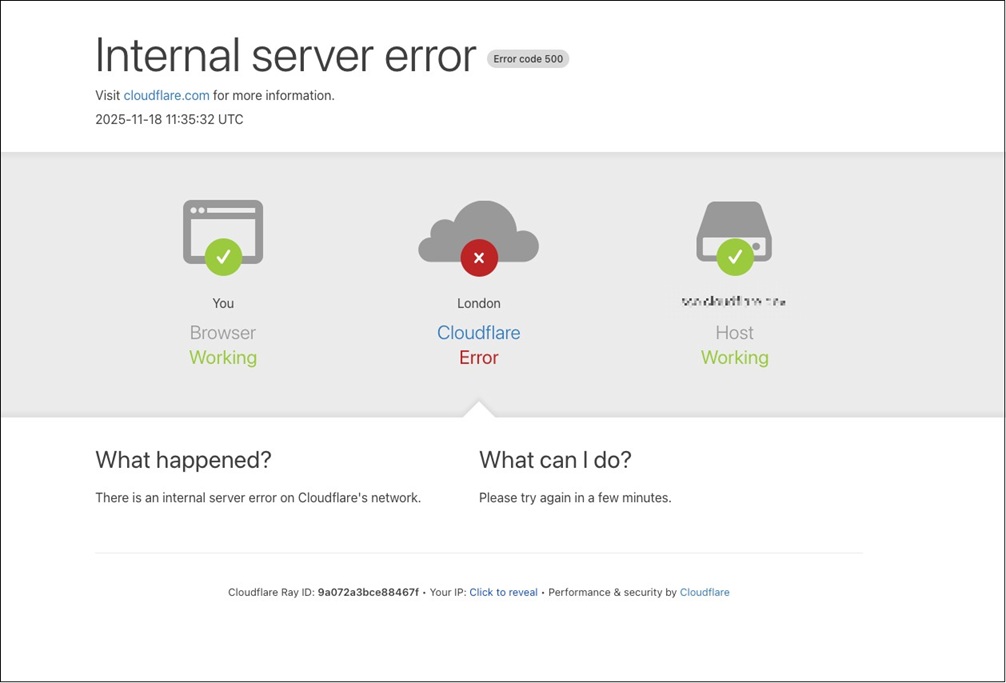
“All requests for websites in this state returned an HTTP 500 error, with the small exception of some test endpoints,” Knecht explained.
React vulnerability set to cause more chaos
Cloudflare’s crash-causing update was rolled out in response to a newly discovered critical vulnerability in ‘React Server Components’, a feature of the programming library ‘React’ which is used extensively in modern web applications.
Though the vulnerability has already seen at least two China threat actors attempt to exploit it since Wednesday, security researcher Kevin Beaumont criticised Cloudflare for moving too hastily on the flaw.
“I don’t think Cloudflare needed to rush out a change to their global service and take it down entirely,” he said.
Jamieson O'Reilly, founder of information security company Dvuln, said he expected the vulnerability to “leave a long trail of destruction”.
“With a vulnerability so critical it's better to over-assume than it is to under,” O’Reilly told Information Age.
“Take an organisation with, say, 100 apps online.
“Maybe only one of those apps is vulnerable – but it only takes one app in the right environment to bring the rest down.”
Although Cloudflare’s Friday outage stemmed from a security update, Knecht stressed it “was not caused, directly or indirectly, by a cyberattack on Cloudflare’s systems or malicious activity of any kind”.
A unified, fragile internet
Salil Kanhere, professor at UNSW Sydney’s School of Computer Science and Engineering, told Information Age that to understand why Cloudflare’s outages had such far-reaching consequences, one needed to look at the structure of today’s internet.
“Over the past decade, global cloud and edge services have consolidated under a handful of dominant providers,” said Kanhere.
“Cloudflare is among the largest because it occupies a pivotal position at the intersection of performance, routing, and security.”
He explained that although many enterprises and startups benefit from Cloudflare’s unified, full-stack solutions, such wide-reaching integrations introduce “systemic risk”.
“When one component of Cloudflare’s platform fails, the disruption cascades across everything connected to it.
“This is not a flaw unique to Cloudflare.
“It reflects the evolution of global digital infrastructure towards greater integration, automation, and centralisation.”
Indeed, Cloudflare’s incidents followed another major outage at Amazon Web Services (AWS) which pushed millions of users offline for three hours in October.
“Recent outages at Cloudflare, AWS, and other providers highlight a clear pattern: our digital economy depends heavily on global infrastructure layers that are deeply interconnected,” said Kanhere.
“When one of these layers fails, the ripple effects spread rapidly across the world.”