Fortnite, Snapchat, Xero, Reddit, Netflix, Instagram, and the websites of Telstra, Optus and NBN Co are recovering after a major outage at Amazon Web Services (AWS) compromised the world’s largest cloud platform, pushing millions of app users offline around the world.
The three-hour outage – which AWS, the cloud arm of Amazon, described as an “operational issue” – began around Australian dinner time on 20 October, frustrating families as streaming services, social media and gaming networks went down at times of peak demand.
Downdetector, which tracks performance issues with major online properties worldwide, observed across-the-board surges in problems for users Australia and elsewhere as the outage increasingly affected “multiple services that depend on AWS infrastructure.”
AWS engineers quickly traced the issue to AWS’s US-EAST-1 data centre region in Northern Virginia, which supports thousands of commercial customers with a full suite of AWS services including AI, video streaming, database, transcription, and other services.
Disruptions to those services were attributed to a domain name system (DNS) error in the API used to access AWS DynamoDB, a core AWS service that processes more than 1 billion database requests per hour for Amazon’s Alexa, Ring, e-commerce, and backend systems.
That left its major users – including gaming services like the PlayStation Network, Steam, and Pokemon Go, e-commerce sites Square, Venmo and Coinbase, and productivity tools Slack, Microsoft Teams and Zoom – unable to access critical parts of their database infrastructure.
“Significant error rates” for DynamoDB requests to servers in the US-EAST-1 region created “increased error rates and latencies”, Amazon said, advising that the issue had also affected Amazon customer support and that customers “continue to retry any failed requests.”
From little things, big pings grow
More than 2,500 companies saw problem reports surge during the outage, Downdetector said in an update, with over 11 million issues reported and 395 companies still affected hours after the outage was said to have been resolved.
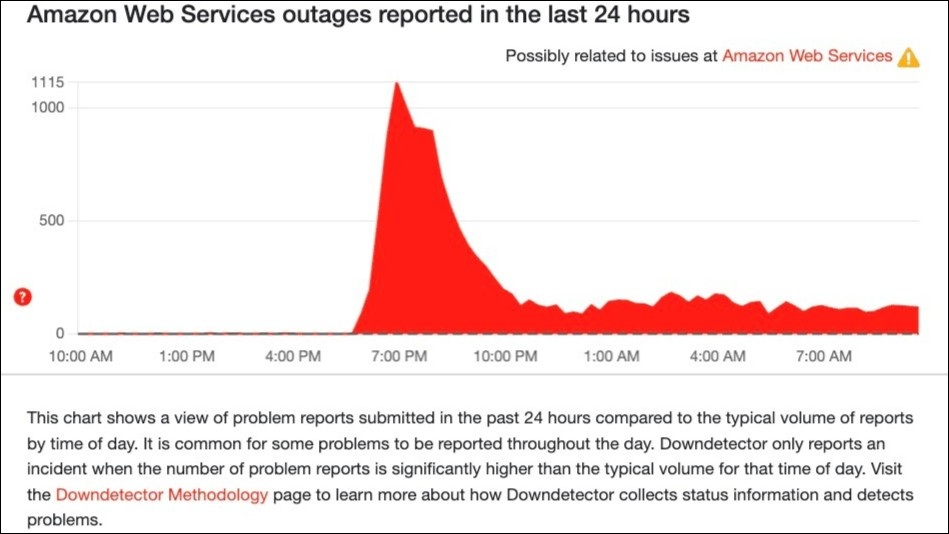
The outage hit just as Australian households were sitting down to stream movies, catch up on socials and hit favourite gaming sites. Image: Downdetector
AWS engineers ultimately narrowed down the outage to an “internal subsystem responsible for monitoring the health of our network load balancers” – and worked, slowly and deliberately, to isolate the cause and implement a fix as other problems persisted.
This included throttling AWS requests and clearing a backlog of events with the AWS Lambda and CloudTrail development and deployment platforms, which are widely used by developers taking advantage of AWS’s extensive suite of application services.
Even as the DynamoDB issue was isolated, customers began having problems creating new EC2 virtual servers – AWS’s fundamental building block, which also relies on DynamoDB, that lets companies scale services to support millions of simultaneous users.
Although AWS allows customers to specify in which part of the world they want their services to run, it was urging them to remove those controls to allow its systems to reroute their application traffic around trouble spots as AWS steadily came back online.
“We are working to fully restore service as quickly as possible,” Amazon said in an update on the “AWS service event”, noting that “some customers still continue to experience increased error rates… due to issues with launching new EC2 instances.”
The risks of cloud centralisation
AWS is by far the world’s largest cloud operator, with 30 per cent of a cloud services market expected to surpass $614 billion ($US400 billion) for the first time this year – particularly as surging AI demand drives the breakneck creation of new cloud data centres.

The fact that a single service blip could disable so many major sites is a reminder of the risks of centralised cloud architectures. Image: Downdetector
Cloud adoption has redefined the IT industry, with major deals like AWS’s Australian whole of government contract and controversial $2 billion ‘Top Secret’ cloud driving it to last year commit $13.2 billion on Australian cloud infrastructure from 2023 to 2027.
Earlier this year, exploding AI adoption drove AWS to boost its Australian commitment, with $20 billion in new data centres now expected to be invested through 2029 – pressuring competing efforts from the likes of Maincode, ResetData, and Sovereign Australia AI.
For all the benefits of cloud infrastructure, however, it’s not flawless: Gartner recently warned that 1 in 4 companies will experience “significant dissatisfaction with their cloud adoption” by 2028 as increased dependence on cloud services exposes weak points.
Experts have regularly warned about the risks of centralising cloud computing services that, as this outage showed, can be tripped up by a single error that – thanks to the design of the crucial DNS system – quickly propagates around the world.
Livid users were discussing the impact of the breach online, with some holding up the incident as a reminder of the importance of segmenting cloud platforms and using redundant design to minimise the impact of inevitable cloud glitches.
The AWS service dashboard showed the outage had affected around 30 AWS services, but by 10am Tuesday – 15 hours after the outage started – AWS was claiming that “all AWS services [have] returned to normal operations”.
Yet despite its claims the issue had been “fully mitigated”, Australian Downdetector users continued to report issues on Tuesday, while one Reddit user raged that Amazon “is trying to gaslight users by pretending the problem is less severe than it really is.”